グーグルがローカルビジネスリスティング情報を作る複雑なプロセスを理解しておこう
地方企業のオーナーにとって、自分の会社がグーグルの検索結果に表示されることは重要だ。しかし、そこに掲載された情報が間違っている場合は、どうやってビジネスリスティングを修正すればいいのだろうか?
今回は、グーグルがビジネスリスティングの作成で行っている複雑なプロセスについて、デビッド・ミームが解説する。
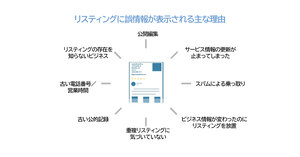
参考までに、デビッドがホワイトボードに描いた図を下に載せておこう。

ローカル情報をちゃんと登録したのに間違った情報が!
僕はデビッド・ミーム。SEOMozでローカル検索戦略担当ディレクターを務めている。今日は、僕らに寄せられる質問の中でもとりわけ多い、次の問いに答えよう。
グーグルに表示されているローカル検索のビジネス情報(ビジネスリスティング)が間違っていたらどうすればいいのか?
自分の会社の名称を入力して検索すると
- 間違った電話番号が表示される
- 間違った住所が表示される
- Googleプレイスで店の位置を示すマーカーが間違った場所に表示される
といったことが、ときどきある。そこで、グーグルがどうやってビジネスリスティングを生成しているかを答えてみたい。
多くののビジネスオーナーが最初にやるのは(これは重要なステップでもある)、直接グーグルに情報を登録することだ。
グーグルは、GoogleプレイスとGoogle+の両方で企業向けのダッシュボードを用意していて、この2つのツールを使ってグーグルに情報を伝えられる。ビジネスオーナーは、これらのダッシュボードに会社の名前、所在地、電話番号、カテゴリのほか、営業時間などを入力して、直接グーグルに通知できる。
これらのツールを使ったビジネスオーナーは当然のことながら、「よし、ビジネスオーナーである私がこの情報をグーグルに通知した。こうしたからには、この情報がグーグルの検索結果で表示されるに違いない」と期待するはずだ。しかし、現実にはそうはならない。実際のところ、グーグルはそんなやり方でビジネスリスティングを生成していないからだ。
グーグルが実際に行っているプロセスについて順を追って説明してみよう。
ビジネスオーナーが入力した情報は、多様なデータソースの一部
さて、多くのビジネスオーナーは、GoogleプレイスのダッシュボードかGoogle+のローカルページのダッシュボードを開き、自分の会社に関する情報を入力する。だが、そうする前に、グーグルがすでにその企業に関する情報を知っていることに気付くだろう。たとえば、グーグルは所在地や電話番号を推測できる。
グーグルはどこからそんな情報を入手しているのか、みんな不思議に思うだろう。
実を言うと、米国には米国企業に関する情報を収集(アグリゲート)している企業が3社ある(「データアグリゲータ」と呼ばれている)。あくまでも米国内に限った話だが、わが国のデータアグリゲータは、Infogroup、Neustar、Axiommの3社だ。グーグルは、これら3社のうち1社以上から情報または情報の使用権を購入して、インデックスに取り込んでいる。
しかし、これらの情報はグーグルのインデックスにそのまま入れられるわけではない。実際には巨大なサーバークラスタに取り込まれ、1つのデータソースとして取り扱われる。
これが何を意味するのか。
ビジネスオーナー(あなた)が入力した情報は、グーグルにとってはこういったデータソースの1つに過ぎず、データプロバイダが別のデータソースとして加わってくるということだ。
たとえば、Infogroupが加わり、次にNeustarが追加されるかもしれない。こんな具合に、次々とデータソースが増加していく。このため、ホワイトボードに描いたこのデータソースの表はデータアグリゲータが加わることで右側にどんどん拡張し、やがてはホワイトボードからはみ出してしまうだろう。
こうして収集された情報はすべて、マウンテンビューかどこかにあるサーバークラスタに集約され蓄積される。
データアグリゲータ以外にもWeb上や行政機関からも
ところがグーグルは、これらのデータアグリゲータ以外の場所からもデータを収集している。これらのデータアグリゲータは、グーグルだけでなく、ウェブ上にあるその他の膨大な数のサイトに対してもデータを提供している。たとえば、YelpやYellowpages.comなどは、こうしたデータアグリゲータの1社からデータを取得している。
そしてグーグルは、そうした情報を掲載しているウェブ上のサイトをクロールし、情報を取得しては、このサーバークラスタに集積している。このことからも、このデータソース表はページからどんどんはみ出し、無限に拡張していくことが想像できるだろう。
ちなみにこのプロセスの仕組みに関しては、僕が作ったローカル検索エコシステムのインフォグラフィックでもう少し詳しく視覚的に説明されている。
さらにグーグルは、データアグリゲータや各種ウェブサイトだけでなく、行政機関の情報も見ている。地域限定的で、特定の郡や州政府に登録してあるような企業なら、グーグルはそういった情報もクロールしているはずだ。行政機関の中には、PDF形式などで情報を公開しているところもある。こういった情報も、この巨大なスプレッドシートのデータポイントの1つとしてグーグルのサーバークラスタに取り込まれる。
これに加えて、まさかと思うかもしれないが、グーグルはGoogleストリートビューからも情報を得ているようだ。SEO by the Seaのビル・スロウスキー氏が、先日ボルチモアで開催されたLocal Universityセミナーの基調講演で、グーグルのストリートビューカーに関する特許について話した。彼の話によると、この特許は、ナビゲーション情報を求めてあちこち回っているグーグルのストリートビューカーのカメラから、店舗名の看板や所在地表示板のある店先の写真を撮影し、その写真から店舗や所在地などの情報を読み取って、ここで僕らが情報クラスタと呼んでいるものに取り込むことを示唆しているという。
「他のデータソース」が間違っていればその情報が表示される
改めて強調すると、グーグルは実に多様なソースから情報を取り込んでいるため、ビジネスオーナーはそうした情報ソースの1つでしかないということになる。
このため、ビジネスオーナーがグーグルに「もしもし、私の店の住所は△△ですよ、電話番号は○○ですよ。私はここで商売をしてるんです
」と教えたとしても、データアグリゲータ、ウェブサイト、行政機関など他のあらゆるデータソースで見つけたデータが間違っていれば、グーグルはその間違ったデータをそのまま取り込んでしまう。グーグルが信頼する多くのデータソース、特に大手データアグリゲータや政府機関などだが、そういった他のデータソースの持っているデータが間違っていた場合、検索結果で誤った情報が表示される可能性が高くなる。
レビュアーの電話確認とGoogleマップメーカー
しかし、グーグルがデータクラスタからこれらの情報を「信頼できる情報」として公開する前に、最後にもう1つの手続きがある。その手続きとは、人間のレビュアーを使ってこの情報を検証するというものだ。
グーグルのレビュアーは、事業所に電話して、カテゴリや店舗が入っているビルの名前などを確認する。レビュアーは、もう1度言うが、オンラインでコンタクトするのではなく、実際の店舗に電話をしてくるんだ。したがって、「もしもし、こちらマウンテンビューですが
」などという電話を受けたら、それは実際にはグーグルのレビュアーかもしれない。そういう電話がかかってきたら、特に注意すべきだろう。彼らは、ウェブ上で見つけた情報を検証しようとしているかもしれないのだから。
レビュアーに関してもう1つ覚えておく必要があるのは、グーグルが「Googleマップメーカー」で他のレビュアーが書き込んだ情報も取り込んでいるということだ。これらのデータソースからの情報が間違っていることに気づいたら、Googleマップメーカーをチェックすることをお勧めする。これは位置情報に関するウィキペディアのようなもので、誰もが入っていってデータを編集できる。
以上のことから、グーグルが公開している間違った情報に悩まされているビジネスオーナーは、単にGoogleプレイスやGoogle+のダッシュボードで情報を修正するだけではまったく不十分で、こうした多様なデータソースのすべてに働きかけを行うことが必要であり、また極めて重要だということがわかるだろう。
国によって主要データアグリゲータは異なるだろうから、米国以外のビジネスオーナーは、自国ではどこの会社がこうしたデータを収集しているかを調べる必要がある。当然のことながら、オンライン電話帳の情報だけではなく、行政機関の情報も更新しなくてはいけないし、少なくともGoogleマップメーカーで店舗情報をチェックする必要があるだろう。と言うのも、これらの情報はすべてこの中核となるデータクラスタに取り込まれた後、グーグルで店舗が検索された場合に結果として表示されるものだからだ。
グーグルが非常に複雑なプロセスを経てビジネスリスティングを作成していることが、少しでもわかってもらえただろうか。さらに詳しい情報を欲しければ、Local Universityで僕と一緒に講演をしたマイク・ブルメンタールのブログが役に立つはずだ。ここで僕が視覚的に説明したことを、マイクはテキストベースのレイアウトでわかりやすく解説している。僕がGoogleローカルのデータクラスタのアイデアを思いついたのも、実はマイクのおかげだ。興味があったら、ぜひ読んでみてほしい。




この記事は、Moz Blog に掲載された以下の記事を日本語訳したものです。
原文:「How Business Listings Are Made - Whiteboard Friday」 by David Mihm (2013/06/06)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。
デジタルマーケティングの即戦力を2日間で育てます! 第24期「企業Web担当者 初級講座」6/13・6/14【2024年6月度】
 4,867 いいね!
4,867 いいね!「第6回 Googleアナリティクス4実践講座~GA4を使いこなす! 計測設定からレポート・分析活用まで」オンライン開催
1,164 いいね!Web担 編集後記 2024年3月
441 いいね!ライオンでアドビのCMSを導入! 導入の背景や活用方法を聞いた
432 いいね!話題の「ChatGPT」こんなに使えたら本当にすごい! 目からウロコの使い方を解説|GPTs活用事例も
289 いいね!【広告主・マーケター限定】デジタルマーケターズサミット 2024 Winter 2/28、29オンラインLIVE配信
258 いいね!【満員御礼】「GA4祭り」をテーマにアクセス解析の専門家が集結! 3月21日(木)@渋谷【Web担当者Forum Meet UP #2】
88 いいね!生成AI「Copilot」でMicrosoft 広告はどう変わる? ―Web担編集長・四谷が根掘り葉掘り聞いてきた!
85 いいね!

ソーシャルもやってます!